
About Me
I am currently a Ph.D. student at Australian Institute of Machine Learning (AIML), Adelaide University, where I also obtained my MPhil degree here in 2024 supervised by Prof. Lingqiao Liu, Dr. Libo Sun and Prof. Ian Reid.
Before joining AIML, I received my bachelor's degree from Beijing University of Posts and Telecommunications (BUPT) in 2022.
My research interests focus on 3D computer vision (including 3D generation, reconstruction, and understanding), as well as introducing 3D representations into broader domains such as generative world models and embodied AI, enabling a deeper understanding of the constraints and rules of the real 3D world.
I'm looking for industrial internship, feel free to reach out!
Publications
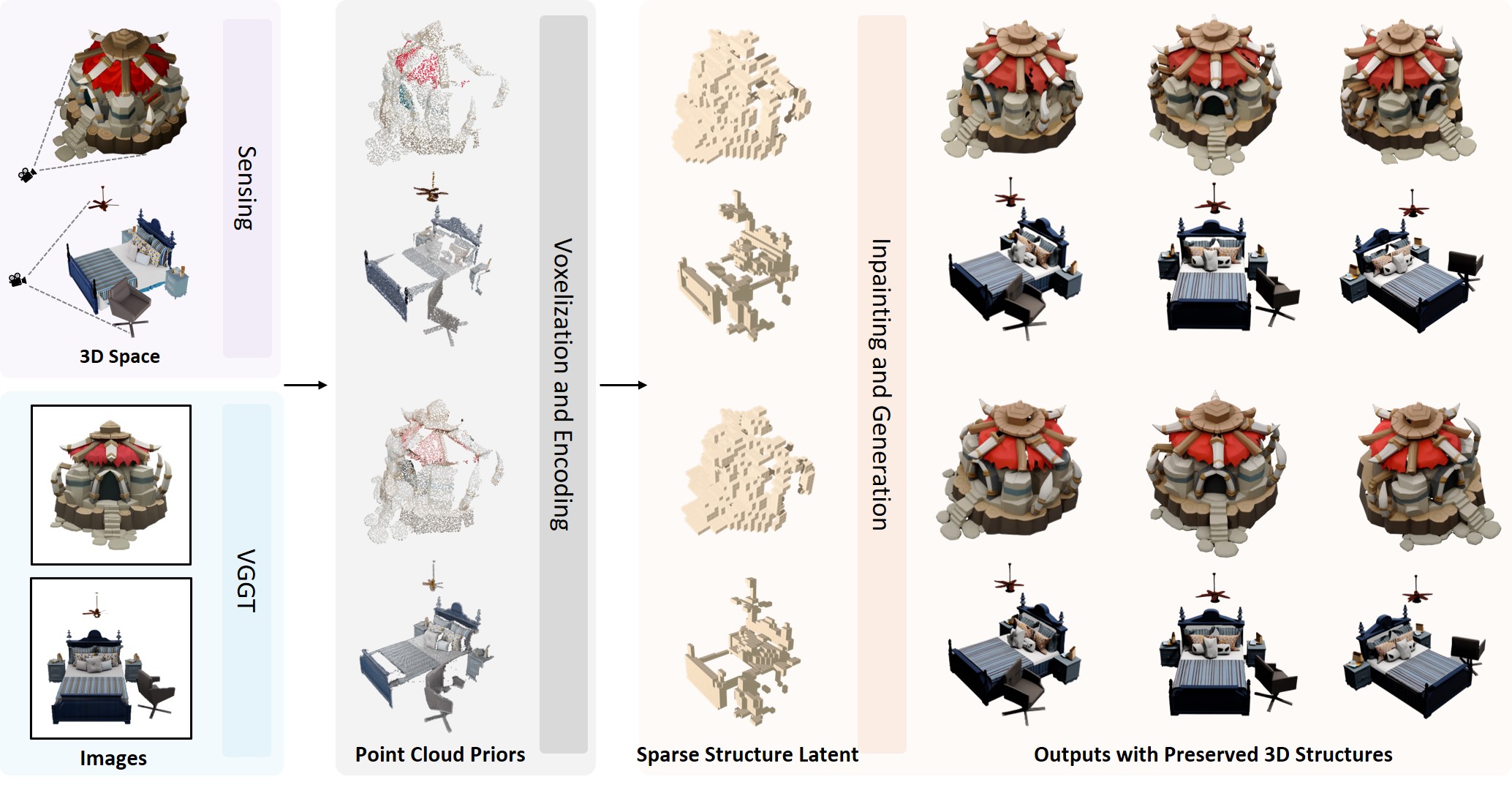
Training-Free Instance-Aware 3D Scene Reconstruction and Diffusion-Based View Synthesis from Sparse Images
Jiatong Xia, Lingqiao Liu
SIGGRAPH Asia, 2025
[Paper]
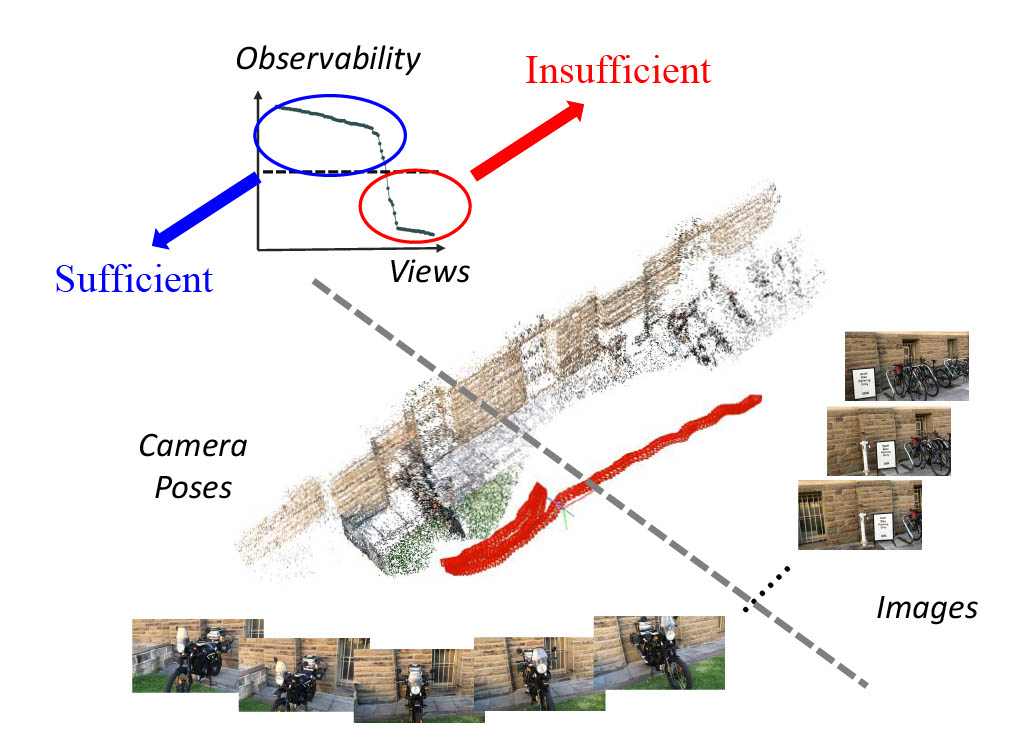
Towards high-quality novel view synthesis from nonuniformly distributed input views
Libo Sun*, Jiatong Xia*, Lingqiao Liu
IEEE Trans. on Visualization and Computer Graphics (TVCG), 2025
[Paper]
Invited Talks
|
|
Invited talk at DICTA2025 workshop: Visual Generative Models: Past, Present, and Future |